
Enriching health research with unstructured patient data: opportunities and challenges
Researchers Involved
Prof. Dr. med. Dr. phil. Nikola Biller-Andorno
PD Dr. med., Dr. med. dent. Dominik Ettlin
Yvonne Ilg
research areas
timeframe
2021 - 2021
contact
gschneid@ifi.uzh.ch
Project Description
Most of the health-related data are unstructured data from different sources. The inclusion of unstructured data such as textual data can add depth to analysis as well as provide additional information to standardized structured data. This can lead, for example, to knowledge enrichment on risk factors or health-relevant behaviors. However, combining data from different sources poses very unique challenges.
In 2021 the DSI Health Community launched two synergistic initiatives for analyzing the needs of the research community to make better use of unstructured data, and for capacity building of text analysis approaches within the DSI community. The joint project consists of two main streams:
Stream 1
This project includes the establishment of an easy-to-access infrastructure for text analytics and corresponding workshops to strengthen capacity building within DSI und the UZH.
Stream 2
A second project stream includes the conduct of a literature review and a survey among UZH researchers to identify community needs and a “unique” niche in the national and international text analytics for health research landscape.
Stream 1
The main purpose of TAP stream 1 is to provide libraries and best practices, including documentation and workshops, to address the tasks of the DSI community health. The first workshop was focused on introduction to text analytics, pre-processing techniques, collocation and keyword detection. In the second workshop we proceed to topics of supervised and unsupervised learning. Finally, in the third workshop, the topics of conceptual maps, word embedding, and deep learning were addressed.
We work with three datasets for our initial studies:
Visual for dipex
Synomyms and associations to “Leben” and “Koerper” in teh MS DipEx Data:

DipEx Patient Interviews (Giovanni Spitale):
The material consists of 13 COVID-19 interviews (7 in Italian, 3 in German, 2 in French, 1 in English) and 41 Multiple Sclerosis interviews (28 in German, 7 in French, 5 in Italian).
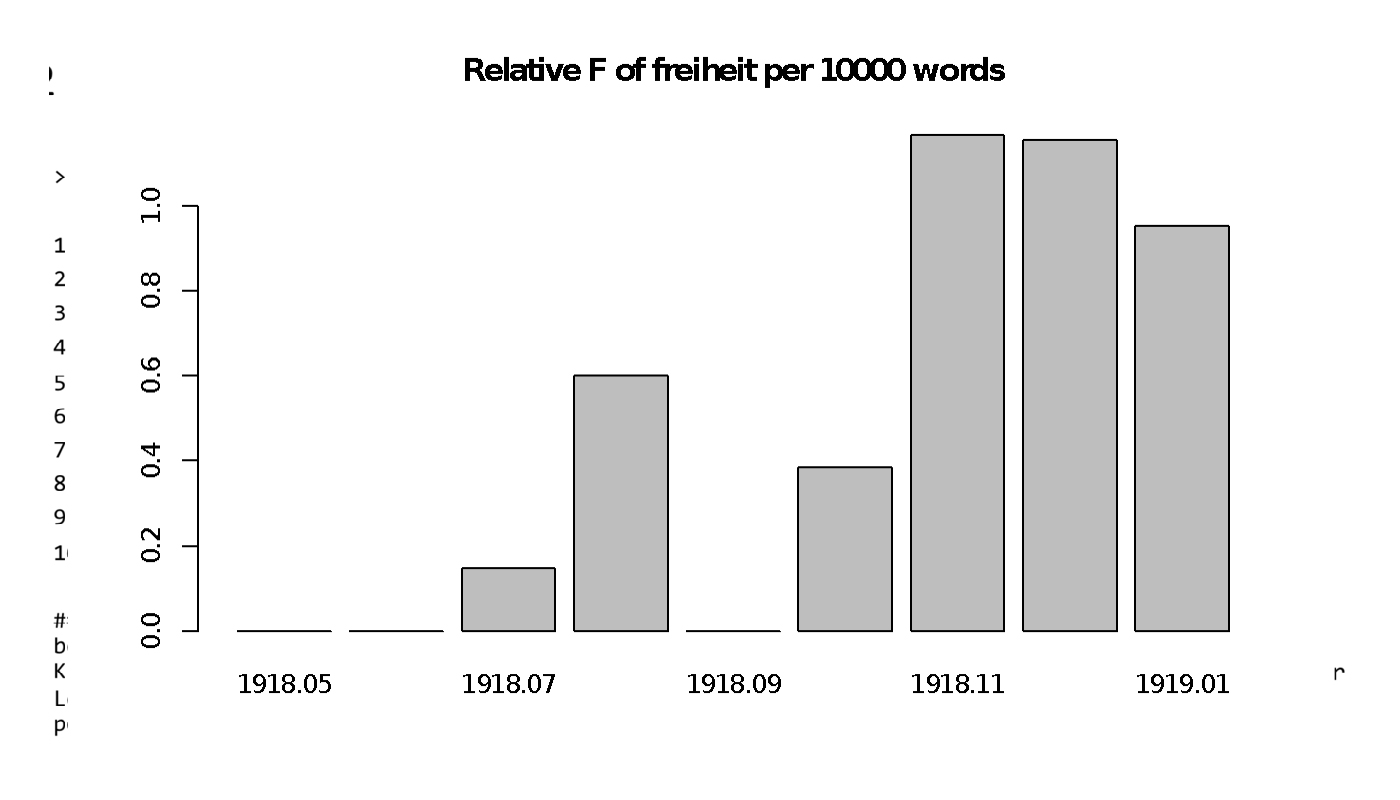
Description VISUAL FOR Spansih Flu
Frequency of the word “Freiheit” in the pandemic. After the first wave it increases a bit because when the number of cases reduces, some liberites are possible again. Towrds the end in increases as the political notion of freedom is important.
Patient records (Dominik Ettlin)
- Dataset experts:
Christian Müller, Jonas Zürcher, Hannah Rohe, Dominik Ettlin, Aleksandra Zumbrunn, Luigi Gallo, Markus Wolf - Dataset language(s):
German (Brazilian Portuguese in a separate data set) - Dataset Format:
Limesurvey formats, queXML format (*.xml), queXML PDF export Tab-separated-values format (*.txt), Printable survey (*.html) - Original purpose of the dataset:
Patient-administered report for clarification of symptoms and symptom-burden (incl. psychosocial burdens) in the orofacial region using 1) free text, 2) pain graphs, 3) a symptom checklist, and 4) algorithm based presentation of case-finding instruments in the form of publicly available, in-depth questionnaires to create response-tailored assessments and to facilitate appropriate referrals for expert assessment.
Stream 2
This project had a first aim to review the scientific literature for examples of and guidelines for working with unstructured data. This extensive review showed that very little generic guidance is available for applied researchers on how to process, analyze, and interpret studies that combine structured and unstructured information. This need for applied guidance war further emphasized by results from a survey among UZH researchers. One of the key survey findings was that researchers face challenges in aligning the work with unstructured data with research question and design. Specifically, one of the most crucial but at the same time most underappreciated step in research is to the find a good hypothesis / research question. This task becomes all the more challenging when unstructured data are intended to be used. Furthermore, there appears to exist very limited guidance on how to approach the formulation of a hypothesis. Regarding this content, we plan to organize a workshop in November to deepen the understanding of what aspects are needed for guiding the process of formulating research question and hypothesis.
Literature review
The main research question: How to reach and ensure proper (systematic, reliable, valid, effective, ethical) integration of unstructured data from different sources into the health research in order to gain new knowledge and enhance the quality of research?
Focus on three fields: cardiology, neurology and mental health
Goals: The literature review aims at gaining an overview of challenges of unstructured data integration and strategies how to deal with them. The literature search should lay the groundwork for the needs assessment within the UZH research community. It should result in a publication and will help us to define the focus of the survey and the follow-up reflection project.
Papers reviewed: 514 papers from two databases (Pubmed, PsychInfo);
Papers included: 28 papers
Preliminary results: Different fields work with different challenges and approaches. The overarching challenge is the lack of guidelines on how to deal with unstructured data in health research.
Survey
The aim of the survey was to assess researchers experiences, wishes, and needs for utilizing unstructured data. We conducted the survey among UZH researchers from the health and other domains. In total, we received 177 answers.
The survey was divided into 5 sectors:
- Demographics
- Motivation, type and use of unstructured data
- Checking usability of framework («research question development»)
- Obstacles encountered when using unstructured data
- Reflection about the unstructured data in the broader scientific context
Results: to be published
Reflection Project
Based on the literature search and the survey results, we will conduct the reflection workshop. The goal of this workshop will be to perform a systematic assessment of the strengths, weaknesses, opportunities, and needs of harvesting and utilizing unstructured data to enrich research studies.